Learning Speed-Adaptive Walking Agent Using Imitation Learning With Physics-Informed Simulation
*Equal Contribution 1Carnegie Mellon University 2University of Michigan, Ann Arbor
Abstract
Overview

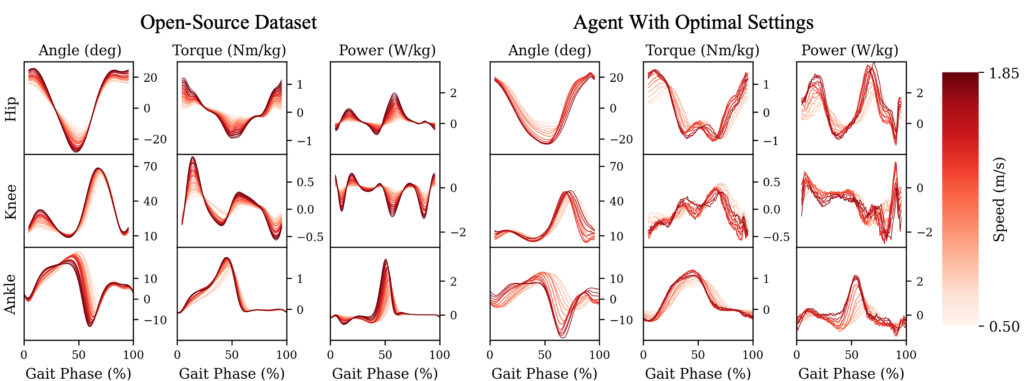
The framework includes two main components: generating expert demonstrations and policy optimization. Expert demonstrations from motion data are used to train a discriminator that distinguishes expert- from policy-generated actions at different speeds. The reward function combines the discriminator’s output with a speed reward (difference between the agent’s target and actual center of mass speed). These rewards optimize the walking policy using trust region policy optimization. The target speed is part of the agent’s observation space, with a progressive curriculum exposing the agent to a range of speeds during training. Evaluation tests the agent’s ability to achieve the desired speed under varying conditions.


Walking agent performance with optimal and baseline settings. (A) Target speed tracking performance across varying conditions. Tracking error for (B) joint angles and (C) COM speed relative to ground-truth data. (D) Walking agent’s adaptability to dynamically changing walking speeds. Error bars and shaded regions indicate ±1 standard deviation, and asterisks indicate statistical significance (p<$ 0.05).
Citation
@misc{chiu2024learningspeedadaptivewalkingagent,
title={Learning Speed-Adaptive Walking Agent Using Imitation Learning with Physics-Informed Simulation},
author={Yi-Hung Chiu and Ung Hee Lee and Changseob Song and Manaen Hu and Inseung Kang},
year={2024},
eprint={2412.03949},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2412.03949},
}